






























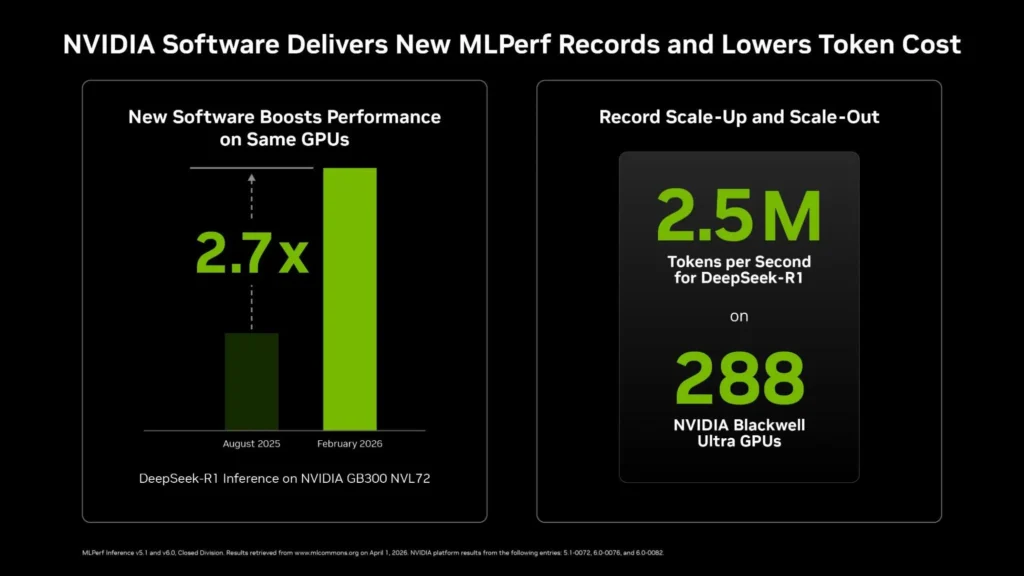
A NVIDIA consolidou sua liderança absoluta no setor de inteligência artificial ao submeter os resultados da mais recente rodada de testes do MLPerf Inference v6.0. Utilizando a nova arquitetura Blackwell Ultra em sistemas GB300 NVL72, a empresa demonstrou um rendimento até nove vezes superior ao de seu concorrente mais próximo, estabelecendo novos recordes de baixo custo por token e eficiência em “fábricas de IA”.

O MLPerf v6.0, organizado pela MLCommons, é considerado um dos conjuntos de testes mais rigorosos da indústria. Nesta versão, foram incluídos modelos de raciocínio avançados e arquiteturas MoE (Mixture of Experts), como o DeepSeek-R1, GPT-OSS-120B e Mixtral 8x7B, desafiando o hardware em cargas de trabalho empresariais reais.
Salto de desempenho via software e hardware
Um dos aspectos mais impressionantes da submissão da NVIDIA é o ganho obtido exclusivamente através de otimizações de software. Sem qualquer alteração física no hardware desde os primeiros testes, a empresa conseguiu um aumento de 2,77x na taxa de transferência de tokens no modelo DeepSeek-R1.
Confira os resultados detalhados obtidos pelo sistema GB300 NVL72:
| Modelo de IA | Modo de Teste | v5.1 (Referência) | v6.0 (Atual) | Salto de Velocidade |
| DeepSeek-R1 | Servidor | 2.907 | 8.064 | 2,77x |
| DeepSeek-R1 | Offline | 5.842 | 9.821 | 1,68x |
| Llama 3.1 405B | Servidor | 170 | 259 | 1,52x |
| Llama 3.1 405B | Offline | 224 | 271 | 1,21x |
Leis de co-design e transparência
De acordo com Jensen Huang, o sucesso da NVIDIA no MLPerf é fruto de “leis de co-design extremas”, onde silício, arquitetura de sistema, design de data center e software são desenvolvidos de forma integrada. Essa abordagem permite que a empresa seja a única a submeter resultados para modelos altamente complexos como o DeepSeek-R1, enquanto concorrentes e fabricantes de ASICs optam por participações mais limitadas.
Para o mercado corporativo, esses números traduzem-se em um melhor Custo Total de Propriedade (TCO). Ao oferecer o maior rendimento por dólar, a NVIDIA atrai clientes que buscam escalar infraestruturas de IA em larga escala, garantindo que notebooks, servidores e clusters de pesquisa operem com a máxima eficiência disponível em 2026.
Fonte da matéria: WWCFtech
Siga o TecLab em todas as mídias: linktr.ee/rbuass
Galindowie • 2 de abril de 2026 às 13:54 GMT-3
0 comentários